Overview
In this article I’d like to focus on how Cloud Run handles concurrency and scaling. Concurrency will allow a single instance to do more work, and scaling will show how more instances can be used to do even more work when the situation arises.
Methods
The methods build on the methods from this GCP service comparison article. In summary:
- a Cloud Run service is loaded with a basic nodejs app that responds to web requests with “Hello, World!”
- the service is configured with 1 CPU and 2 GB of memory
- a Cloud Shell instance close to the service is used to generate web requests that slam the Cloud Run service
In that article, the service was only allowed to handle one request at a time and only one instance was allowed to be running at a time. This gave a baseline for the service, but both of these two things are going to be changed during the experiments here.
Concurrency
The default level of concurrency for a Cloud Run service is set at 80 concurrent requests. This means that the load balancer sending requests to the service will send 80 requests at a time to the service before considering that the service is full. A service that is full will handle a request, return it, and only then will the load balancer send another request to the service.
The concurrency experiment here will be about setting the service at different levels of concurrency to see how it responds. My guess is that there will be a sweet spot of how many requests the service (running this Hello World app) can handle before the service overloads and the requests start taking longer to respond than would be ideal.
Load Generation
Hey: https://github.com/rakyll/hey
To test the request throughput and latency distribution, “Hey” will again be used to generate the request load against the service. Hey will be used with different levels of concurrency until 95% of requests are returned under 100 ms.
Scaling
Cloud Run instance autoscaling reference: https://cloud.google.com/run/docs/about-instance-autoscaling
I would like to answer several questions around scaling services with Cloud Run:
- How long do new instances take to spin up?
- Does adding more instances allow for linearly more work to be done?
- Given some scaling headroom, how many instances are spun up to handle some amount work?
To answer the question about instance spin up time, the test will require the services to be “cold” (where no instances are ready to handle requests).
A single instance baseline will need to be tested first to get information about how a single instance spins up and how much throughput it can handle. Once this is known, this value can be used to guess how much work X instances will be able to handle. The experiments should then be able to check this guess against real data.
Load Generation
“Hey” will be used to generate load for this test as well.
Note: I ran into the maximum data that Hey can report which makes the later experiments’ data a bit incorrect. Hey can gather and report on 1,000,000 requests during a run and any requests after this will not be aggregated into the reported statistics. I checked the Hey source code to see if this same thing held true for the throughput reporting but it doesn’t seem to use the same mechanism for reporting. So the “Number of Requests that Timed Out” value will not be correct (as indicated with a “?”), but the request throughput should be accurate.
Service Revision Changes
What happens when a service is configured to run some code (A) but is then updated to run some new code (B)?
If the service is cold, then the other experiments in this article will tell us what would happen. But, if the service is currently performing work with the original code and then swapped over to the new code, these experiments won’t tell us what would happen.
This question and experiment seems related to the above, but is subtly different so needed its own section.
Changing Revisions
A service revision change can be caused by a change in the service configuration (max/min number of instances, max concurrency, etc) or in the code that the service should run.
In this case, to get good results from the experiment, nothing should change but the service should be tricked into thinking a new revision needs to be created. A new service revision can be created where it looks exactly like the previous revision and Cloud Run will swap all the traffic to the new revision.
Concurrency Experiments
The source code is available here: project setup and services creation code
Steps:
The Cloud Run service is loaded with the “hello world” app and set to 1 CPU, 2 GB of memory, and 1 max instance.
The service is set to the level of service concurrency that is being tested.
The service url is hit to make sure that the service is “warm” (active and ready to accept requests).
“Hey” is used to generate load for 5 minutes at the level of load concurrency that is being tested.
hey -z 5m -c [hey concurrency] [service url]
Max Concurrency Experiment
The Cloud Run configuration was changed to allow an instance to handle up to 80 concurrent requests. “Hey” was used to generate different levels of concurrency for 5 minute durations. This is still with a single instance of Cloud Run.
| Hey Concurrency | Requests/sec | Percent Requests Under 100 ms | Num Requests Timed Out |
|---|---|---|---|
| 70 | 773 | 50% | 17 |
| 60 | 773 | 75% | 0 |
| 50 | 757 | 75% | 0 |
| 40 | 771 | 90% | 0 |
| 30 | 772 | 95% | 0 |
| 20 | 717 | 95% | 0 |
| 10 | 644 | 99% | 0 |
30 concurrent requests seems to be the sweet spot for this setup. Above this number of concurrent requests and the request throughput doesn’t really change but the latency distribution changes to make more of the requests slower (for example, only 50% of requests being under 100ms).
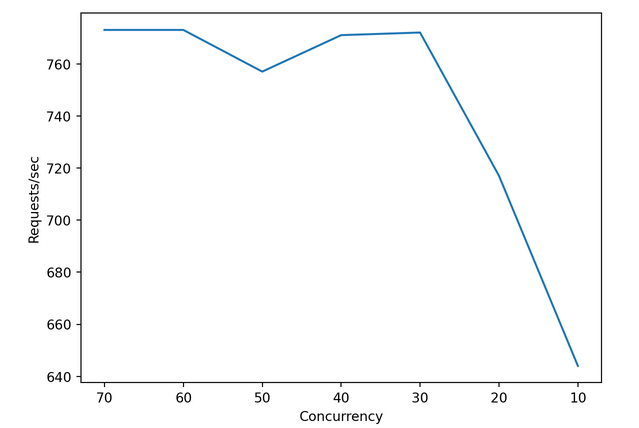
The screenshot below of the internal service request latency metrics also shows that the service (running our Hello World app) can’t consistently deal with concurrency higher than 30 requests at a time.
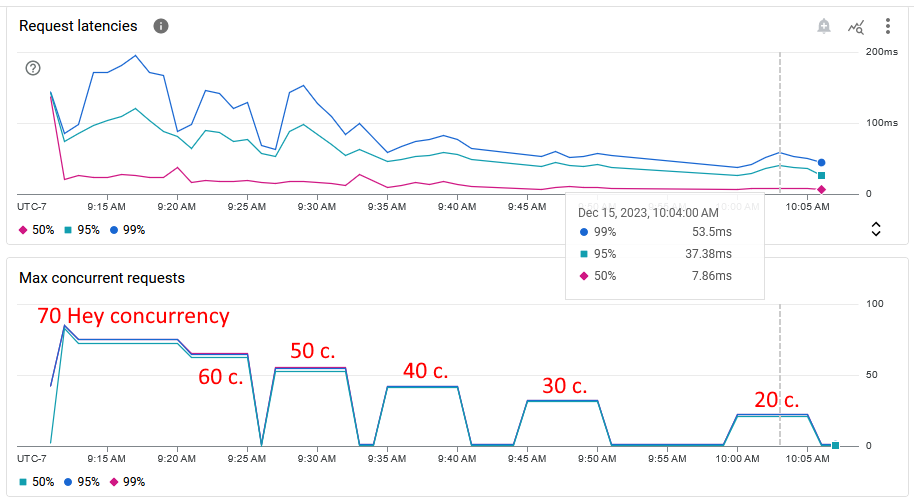
The throughput results seem to be averaging around 770 requests per second which is 3.5 times higher than with single concurrency (219 requests per second). Also, the throughput results seem to be way more stable than with single concurrency which had a request throughput variability of around 20%.
Max Concurrency Experiment Verification
Cloud Run was updated to only allow for up to 30 concurrent requests (which was found as the sweet spot for this Hello World app). “Hey” was then used to generate requests above and below this amount to see how the service responded.
| Hey Concurrency | Requests/sec | Percent Requests Under 100 ms | Num Requests Timed Out |
|---|---|---|---|
| 50 | 768 | 75% | 8 |
| 40 | 783 | 75% | 0 |
| 30 | 725 | 90% | 0 |
| 30 (test 2) | 782 | 90% | 0 |
| 20 | 717 | 95% | 0 |
30 concurrency seems to be close to the “correct” amount of instance concurrency. It wasn’t able to achieve 95% of requests under 100 ms, but under this level of concurrency and the request throughput dropped quite a bit. The ideal amount of concurrency for these tests would probably be around 25 - 27 service concurrency, but the current value will be close enough for these experiments.
Note: the test with 30 Hey concurrency was run twice. During the first run, the service internal metrics reported a really strange request latency metrics blip where some of the requests took a really long time. During the second run, the service internal metrics were within expected results and the throughput was more expected. A screenshot of the latency blip can be found below and more experiment screenshots can be found at the above “Result Screenshots” link.
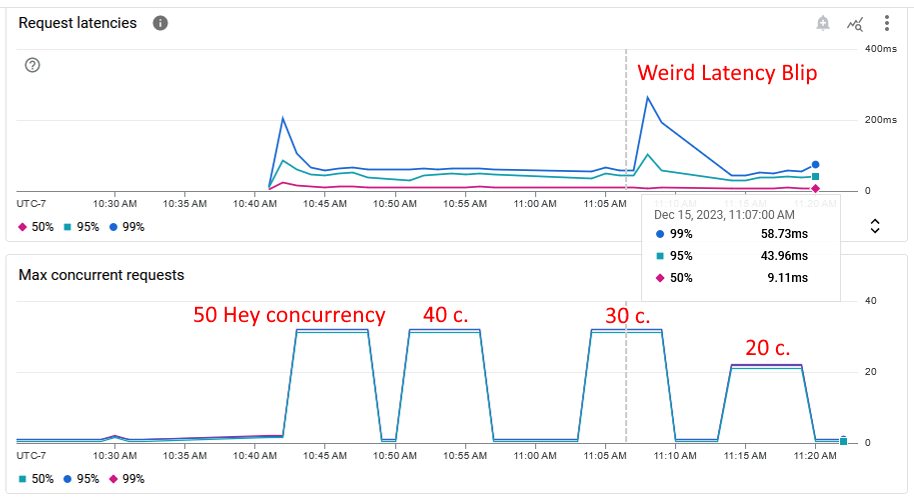
Scaling Experiments
The source code is available here: project setup and services creation code
Steps:
The Cloud Run service is loaded with the “hello world” app and set to 1 CPU, 2 GB of memory, and 30 max concurrency per instance (which was found in the above concurrency experiment).
The service is set to the number of max service instances that is being tested.
The internal service metrics are checked to make sure that the service is “cold” (no service instances are ready to process requests).
“Hey” is used to generate load for 5 minutes at the level of load concurrency that is being tested.
hey -z 5m -c [hey concurrency] [service url]
Single Instance Baseline Experiment
To determine a baseline for scaling services, this service was configured for a single max instance and Hey was run with 30 concurrency. This experiment was run twice.
| Run | Requests/sec | Num Requests Timed Out | Average Container Startup Time |
|---|---|---|---|
| 1 | 676 | 17 | 1.49 seconds |
| 2 | 662 | 10 | 1.49 seconds |
A single cold instance with this setup had a throughput of around 669 requests per second and could start new instances in about 1.5 seconds.
This throughput is around 13% slower than a warm instance and had some requests that timed out.
Two Instances Experiment
In this experiment, the number of max instances was raised to two.
First, “Hey” was run with 30 concurrent requests which a single instance could handle. Second, “Hey” was run with 60 concurrent requests which both instances should be able to handle together.
| Hey Concurrency | Requests/sec | Num Requests Timed Out | Average Container Startup Time | Num Instances |
|---|---|---|---|---|
| 30 | 1,300 | 14 | 1.49 seconds | 2 |
| 60 | 1,458 | 27 | 0.41 seconds | 2 |
Two instances should be able to handle 1,338 requests per second (based on the results from the single instance of 669 requests per second). The two instances were able to hit the calculated throughput.
The average container startup time during the second test seems curious. Maybe the container instance was cached close to where the Cloud Run instance was being spun up?
During the first test with 30 Hey concurrency, two instances were spun up to handle the requests.
Three Instances Experiment
In this experiment, the number of max instances was raised to three. The experiment was run three times, once with 30 Hey concurrency, once with 60, and lastly with 90.
| Hey Concurrency | Requests/sec | Num Requests Timed Out | Average Container Startup Time | Num Instances |
|---|---|---|---|---|
| 30 | 1,854 | 14 | 1.23 seconds | 3 |
| 60 | 1,981 | 49 | 1.20 seconds | 3 |
| 90 | 2,015 | 50 | 1.20 seconds | 3 |
Three instances should be able to handle 2,007 requests per second (669 x 3). The three instances were able to hit the calculated throughput.
During the first test with 30 Hey concurrency, three instances were spun up to handle the requests.
Five Instances Experiment
In this experiment, the number of max instances was raised to five. The experiment was run twice, once with 30 Hey concurrency and once with 150.
| Hey Concurrency | Requests/sec | Num Requests Timed Out | Average Container Startup Time | Num Instances |
|---|---|---|---|---|
| 30 | 2,378 | 16 | 0.80 seconds | 5 |
| 150 | 3,389 | 52? | 1.34 seconds | 5 |
Five instances should be able to handle 3,345 requests per second (669 x 5). The five instances were able to hit the calculated throughput.
Hey’s reporting limitations were hit during the test with 150 Hey concurrency. This issue was described above here.
During the first test with 30 concurrency, five instances were spun up to handle the requests.
Ten Instances Experiment
In this experiment, the number of max instances was raised to ten. The experiment was run twice, once with 30 Hey concurrency and once with 300.
| Hey Concurrency | Requests/sec | Num Requests Timed Out | Average Container Startup Time | Num Instances |
|---|---|---|---|---|
| 30 | 2,287 | 25 | 0.93 seconds | 9 then 5 |
| 300 | 5,049 | 126? | 0.39 seconds | 10 - 11 |
| 300 (test 2) | 5,660 | 87? | 0.97 seconds | 10 |
Ten instances should be able to handle 6,690 requests per second (669 x 10). The ten instances were NOT able to hit the calculated throughput. The test with 300 Hey concurrency was run twice to see if the first run was abnormal. There was a lot of variability to the internal request latencies which makes it seem like there wasn’t enough time for the results to stabilize. Screenshots can be found in the above “Results Screenshots” link.
Hey’s reporting limitations were hit again during the tests with 300 Hey concurrency. This issue was described above here.
This was the first time where the max number of instances weren’t spun up to handle the 30 concurrent Hey requests test. Only 9 instances were spun up to begin with and, over the course of the test, the number of instances were dropped to 5 active instances.
Ten Warm Instances Experiment
Because of the variability in the above test with 10 cold instances, I wanted to see if more stable results could be achieved if the instances were warm.
In this experiment, 300 concurrent Hey requests were sent to ten warm instances instead of cold instances.
| Hey Concurrency | Requests/sec | Num Requests Timed Out | Average Container Startup Time | Num Instances |
|---|---|---|---|---|
| 300 | 7,162 | 1? | 0.71 seconds | 13 then 10 |
Ten warm instances should have been able to handle 7,700 requests per second (770 requests per warm instance x 10), but the instances weren’t able to hit this number. The results from the warm test were off from the calculated result by 7% while the results from the cold test were off by 15% (best case). This suggests that ideal results can’t be achieved at higher scaling amounts. More work can still be done with more instances, but there is some attenuation.
Even though ten instances were warm and idling waiting for requests, the autoscaler started 3 more instances to handle the requests before scaling back to 10 instances.
Revision Change Experiments
The source code is available here: project setup and services creation code
Steps:
The Cloud Run service is loaded with the “hello world” app and set to 1 CPU, 2 GB of memory, 1 max instance, and 30 max concurrency.
The internal service metrics are checked to make sure that the service is “cold” (no service instances are ready to process requests).
“Hey” is used to generate load for 5 minutes at 30 concurrency.
hey -z 5m -c 30 [service url]
The service is tricked into creating a new revision in the middle of the test. Basically, the same code is deployed again with the same service settings to trigger a new revision but with no changes.
Single Instance to Single Instance Revision Change
In this experiment, a single cold instance is hit with Hey like normal, but then a revision is triggered in the middle of the test. Nothing in the instance will change, but the same code will be redeployed to Cloud Run which will make a new revision anyway.
| Hey Concurrency | Requests/sec | Num Requests Timed Out | Average Container Startup Time |
|---|---|---|---|
| 30 | 687 | 13 | 1.36 & 1.02 seconds |
| 30 (test 2) | 678 | 15 | 1.23 & 0.93 seconds |
The original test of a single cold instance gave a throughput of around 669 requests per second (and 17ish requests timed out). In this test the request throughput ended up being around 682 requests per second. So changing a revision in the middle of a test didn’t really have much of an impact to request throughput.
Internal Metrics
It was difficult to figure out when the new revision was loaded when looking at the metrics from the original test. Because of this, the second test was started exactly at 8:55:00 PM (concluding at 9:00:00 PM) and the second revision was loaded at 8:57:12 (as reported by the revision creation timestamp). This gave exact times that could be compared to the internal metrics.
The internal metrics start reporting a few minutes before the test started and for several minutes after the test ended. Also, the second revision’s instance isn’t shown to spin up when it actually spun up. This makes it complicated to see exactly what is happening on this timescale of minutes, but:
- the first revision’s instance was spun up and started handling requests
- the second revision’s instance was spun up in the middle of the test and started handling requests
- the first and second revision were both handling requests at the same time for just a bit of time (this didn’t happen for too long because the request throughput for this test wasn’t too much higher than a single instance handling all requests)
- the first revision’s instance was spun down
- the second revision’s instance finished handling the requests before spinning down
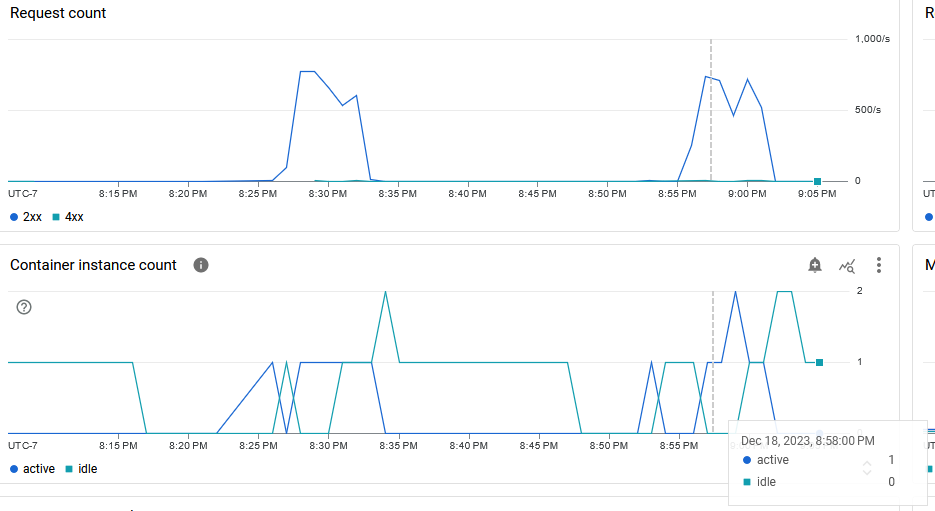
Final Thoughts
It seems that more concurrency helps give consistency to a service’s throughput. There is still some variation, but the results are smoother.
Scaling seems to allow for linearly more work to be done. There is some tapering at higher scaling levels which could go away over longer durations, or this tapering will need to be taken into account when calculating the number of instances needed to do work. It also looks like more scaling allows for the instances to spin up faster.
There are a few things to note though:
- The autoscaler will scale up more instances than are required to do the work (5 instances are spun up but 1 instance could have done the work). Though, this will make the work complete faster and the request throughput better.
- The autoscaler will sometimes spin up more instances than are configured to be spun up (spins up 13 when the max should be 10). So this will need to be kept in mind - and protections put in place - if the work that needs to be done should have a hard maximum (like only 1 instance can be running at a time).
Overall, Cloud Run responds nicely with concurrency and scaling. These settings are very easy to change and the changes can be seen pretty much immediately. The internal metrics reporting gets a bit strange when looking at granular timescales, but should smooth out in larger aggregate timescales.
Comments
Leave a comment: